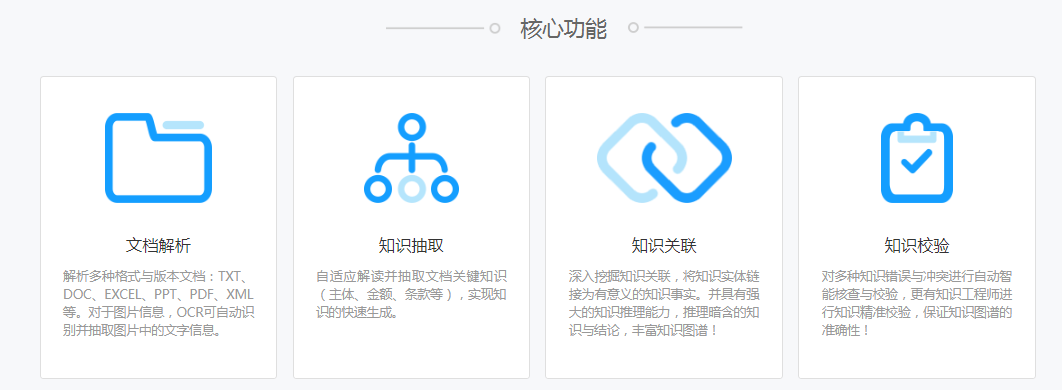
產品介紹
隨著信息技術的不斷發展,互聯網上的信息也在急劇膨脹,在這海量的信息中,各類信息混雜在一起,要想充分利用這些信息資源就要對它們進行整理,如果由人來做這項工作,已經是不可能的,而如果面對中文信息不采用分詞技術,那么整理的結果就過于粗糙,而導致資源的不能充分利用。通過引入分詞技術,就可以使機器對海量信息的整理更準確更合理,使得檢索結果更準確,效率也會大幅度的提高。
但由于中文詞與詞之間不象西文那樣有明顯的分隔符,所以構成了中文在自動切分上的困難。在現有的中文自動分詞方法中,基于詞典的分詞方法占有主導地位。而中文分詞的主要困難不在于詞典中詞條的匹配,而是在于切分歧義消解和未登錄詞語的識別。在中文分詞過程中,這兩大難題一直沒有完全突破。
1、歧義處理
歧義是指同樣的一句話,可能有兩種或者更多的切分方法。目前主要分為交集型歧義、組合型歧義和真歧義三種。其中交集型歧義字段數量龐大,處理方法多樣;組合型歧義字段數量較少,處理起來相對較難;而真歧義字段數量更少,且很難處理。 分詞歧義處理之所以是中文分詞的困難之一,原因在于歧義分為多種類型,針對不同的歧義類型應采取不同的解決方法。除了需要依靠上、下文語義信息;增加語義、語用知識等外部條件外,還存在難以消解的真歧義,增加了歧義切分的難度。同時未登錄詞中也存在著歧義切分的問題,這也增加了歧義切分的難度。所以歧義處理是影響分詞系統切分精度的重要因素,是自動分詞系統設計中的一個 困難也是 核心的問題。
2、未登錄詞識別
新詞,專業術語稱為未登錄詞。也就是那些在字典中都沒有收錄過詞。未登錄詞可以分為專名和非專名兩大類。其中專名包括中國人名、外國譯名、地名等,而非專名包括新詞、簡稱、方言詞語、文言詞語、行業用詞等。 無論是專名還是非專名的未登錄詞都很難處理,因為其數量龐大,又沒有相應的規范,而且隨著社會生活的變遷,使未登錄詞的數量大大增加,這又為未登錄詞的識別增加了難度。
北京理工大學大數據搜索與挖掘實驗室張華平主任研發的NLPIR大數據語義智能分析技術是滿足大數據挖掘對語法、詞法和語義的綜合應用。NLPIR大數據語義智能分析平臺是根據中文數據挖掘的綜合需求,融合了網絡采集、自然語言理解、文本挖掘和語義搜索的研究成果,并針對互聯網內容處理的全技術鏈條的共享開發平臺。