產品介紹
隨著中國的經濟迅速發展和對外交往的日益頻繁,中文在 上的地位也逐步提高。盡管中文被認為是世界上最難學的語言之一,但近年來,世界上學中文的人還是不斷增加,這些人遍布亞洲、歐洲、美洲、非洲。而學習中文的人也不單純是學習語言、文化、歷史專業的學生,許多國家學習經濟、貿易、法律專業的大學生也開始學習中文,他們認為掌握中文會對就業和工作有幫助。
中文信息處理分為漢字信息處理與漢語信息處理兩部分,具體內容包括對字、詞、句、篇章的輸入、存儲、傳輸、輸出、識別、轉換、壓縮、檢索、分析、理解和生成等方面的處理技術。用計算機來處理漢語信息,就是漢語信息處理,又稱中文信息處理。
中文信息處理句法分析和語義分析問題;中文信息處理應用研究的問題,比如信息輸入中的鍵盤輸入和漢字識別發展已經成熟,但語音識別卻很實現,困難是要適應不同人之間的語音變化以及外界的噪音干擾;中文信息處理研究分散而且存在著低層次重復、缺乏統一規范和標準的問題;現代漢語研究領域和計算機領域的隔絕狀態沒有出現根本性改變;漢語文和少數民族語言文字的信息處理技術與 水平相比,還有相當大的差距。
北京理工大學大數據搜索與挖掘實驗室張華平主任研發的NLPIR大數據語義智能分析技術是滿足大數據挖掘對語法、詞法和語義的綜合應用。NLPIR大數據語義智能分析平臺是根據中文數據挖掘的綜合需求,融合了網絡采集、自然語言理解、文本挖掘和語義搜索的研究成果,并針對互聯網內容處理的全技術鏈條的共享開發平臺。
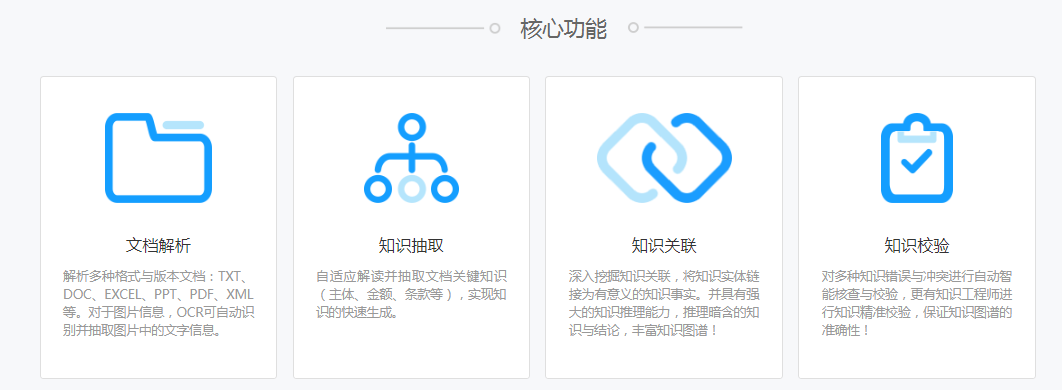
NLPIR大數據語義智能分析平臺主要有采集、文檔轉化、新詞發現、批量分詞、語言統計、文本聚類、文本分類、摘要實體、智能過濾、情感分析、文檔去重、全文檢索、編碼轉換等十余項功能模塊,平臺提供了客戶端工具,云服務與二次開發接口等多種產品使用形式。各個中間件API可以無縫地融合到客戶的各類復雜應用系統之中,可兼容Windows,Linux, Android,Maemo5, FreeBSD等不同操作系統平臺,可以供Java,Python,C,C#等各類開發語言使用。