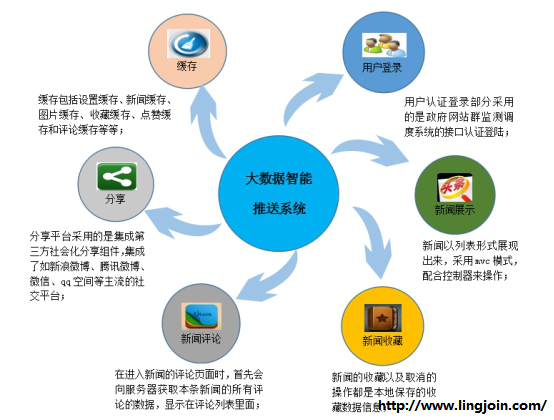
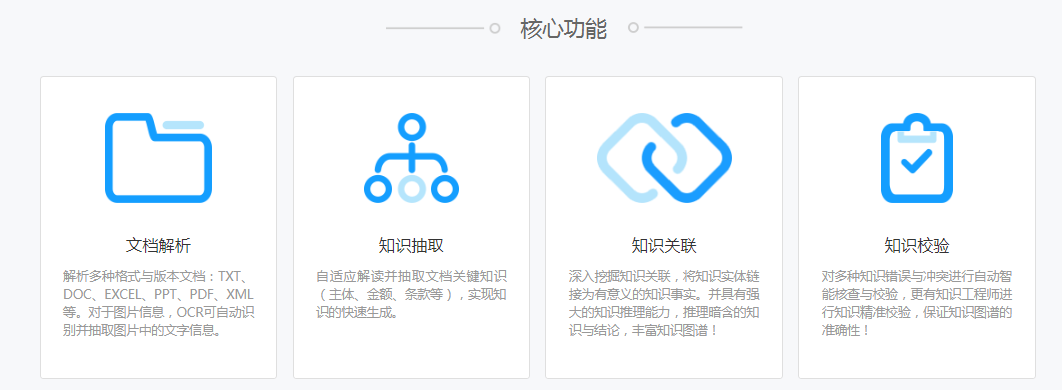
產品介紹
在當今信息爆炸的時代,伴隨著社會事件和自然活動的大量產生(數據的海量增長),人類正面臨著“被信息所淹沒,但卻饑渴于知識”的困境。隨著計算機軟硬件技術的快速發展、企業信息化水平的不斷提高和數據庫技術的日臻完善,人類積累的數據量正以指數方式增長。
數據挖掘是一個多學科領域,它融合了數據庫技術、人工智能、機器學習、模式識別、模糊數學和數理統計等新技術的研究成果,可以用來支持商業智能應用和決策分析。例如顧客細分、交叉銷售、欺詐檢測、顧客流失分析、商品銷量預測等等,目前廣泛應用于銀行、金融、醫療、工業、零售和電信等行業。數據挖掘技術的發展對于各行各業來說,都具有重要的現實意義。
數據挖掘技術具有以下特點:
1.?處理的數據規模十分龐大,達到GB、TB數量級,甚至更大。
2.?查詢一般是決策制定者(用戶)提出的即時隨機查詢,往往不能形成準確的查詢要求,需要靠系統本身尋找其可能感興趣的東西。
3.?在一些應用(如商業投資等)中,由于數據變化迅速,因此要求數據挖掘能快速做出相應反應以隨時提供決策支持。
4.?數據挖掘中,規則的發現基于統計規律.因此,所發現的規則不必適用于所有數據,而是當達到某一臨界值時,即認為有效.因此,利用數據挖掘技術可能會發現大量的規則。
5.?數據挖掘所發現的規則是動態的,它只反映了當前狀態的數據庫具有的規則,隨著不斷地向數據庫中加入新數據,需要隨時對其進行更新。
北京理工大學大數據搜索與挖掘實驗室張華平主任研發的NLPIR大數據語義智能分析技術是滿足大數據挖掘對語法、詞法和語義的綜合應用。NLPIR大數據語義智能分析平臺是根據中文數據挖掘的綜合需求,融合了網絡采集、自然語言理解、文本挖掘和語義搜索的研究成果,并針對互聯網內容處理的全技術鏈條的共享開發平臺。
NLPIR大數據語義智能分析平臺主要有采集、文檔轉化、新詞發現、批量分詞、語言統計、文本聚類、文本分類、摘要實體、智能過濾、情感分析、文檔去重、全文檢索、編碼轉換等十余項功能模塊,平臺提供了客戶端工具,云服務與二次開發接口等多種產品使用形式。各個中間件API可以無縫地融合到客戶的各類復雜應用系統之中,可兼容Windows,Linux, Android,Maemo5, FreeBSD等不同操作系統平臺,可以供Java,Python,C,C#等各類開發語言使用。