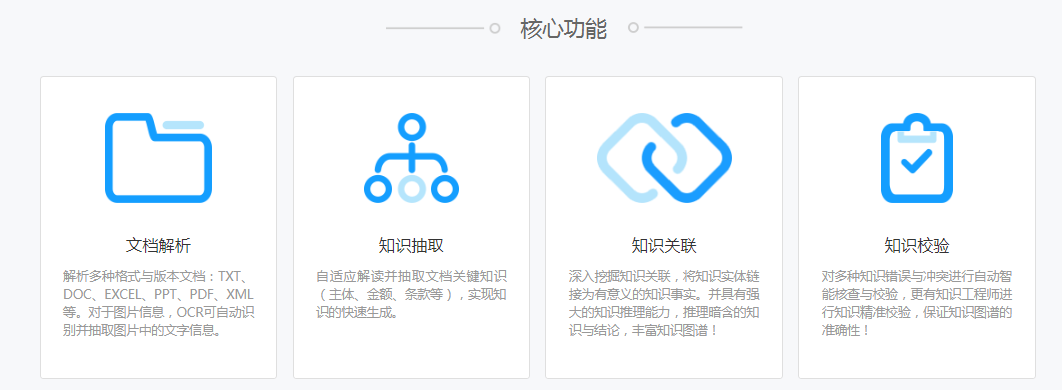
產品介紹
在信息化建設的過程中,數據分為三種類型: 結構化數據、非結構化數據、半結構化數據.隨著互聯網、物聯網、云計算、3G、4G等技術的出現與普及,產生數據的設備也越來越多范圍越來越廣,大量非結構化數據,每時每刻都在產生并且傳播開來.如視頻、圖片、交互網站等,這些海量的數據顯然不能被存儲在預定義的結構化表格中,相反,這些數據甚至來不及用傳統的數據管理模式來分析、存儲和管理,這就是大數據.如何從海量的數據中分析和獲取特定的需求信息,這就是研究大數據的意義。
北京理工大學大數據搜索與挖掘實驗室張華平主任研發的NLPIR大數據語義智能分析技術是對語法、詞法和語義的綜合應用。NLPIR大數據語義智能分析平臺平臺是根據中文數據挖掘的綜合需求,融合了網絡采集、自然語言理解、文本挖掘和語義搜索的研究成果,并針對互聯網內容處理的全技術鏈條的共享開發平臺。
其中KGB(Knowledge Graph Builder)知識圖譜引擎是我們自主研發的知識圖譜構建與推理引擎,基于漢語詞法分析的基礎上,采用KGB語法實現了實時 的知識生成,可以從非結構化文本中抽取各類知識,并實現了從表格中抽取指定的內容等。KGB同時可以定義不同的動作,如抽取動作,并能自定義各類后處理程序。利用KGB知識圖譜引擎可以抽取到產品的詳細報價信息,方便進行下一步的數據挖掘與圖譜構建。
例如KGB語法:
Knowledge: { [/LE;/w]+[采購方;甲方;發包方; 需方]} +1+{[-(/LE;/w)]20}s+{[(/LE;/w)]}
Action: Extract
Argument:甲方單位
表示的是:
如果 句首或者標點后,跟了{采購方;甲方;發包方};后面1步內跟的不是標點也不是是句尾,20個單元內的部分,將選中的詞抽取為甲方單位。
因此,數據挖掘技術是一個發展十分快的領域,?隨著對數據挖掘技術在各領域日益廣泛的應用,實現了數據資源共享及技術發展的跨域,從而大大提高了工作效率,并帶來巨大的成功。21世紀是信息時代的社會,“信息不僅是資源,更是財富”,要實現經濟的騰飛,需依賴高新尖科技的發展,故利用提供的信息,充分進行數據挖掘,則將為數據庫的應用開辟了廣闊的前景,也為人類的文明開辟了一個嶄新的時代。