產品介紹
隨著信息技術的高速發展、數據庫管理系統的廣泛應用,人們積累的數據量急劇增長,大量的信息給人們帶來方便的同時,也帶來了諸如:信息過量難以消化,信息真假難以辨識,信息安全難以保證,信息形式不一致難以統一處理等問題。如何從海量的數據中提取有用的知識成為當務之急。數據挖掘就是為順應這種需要應運而 展起來的數據處理技術。
大數據挖掘是伴隨者互聯網的普及應用和傳統信息檢索技術的不足提出并發展起來的。大數據挖掘是從大數據中發現有用的模式(其中的數據可以存放在數據庫、數據倉庫或其他信息庫中),它旨在解決數據挖掘、信息檢索、知識抽取以及更廣泛的商業問題。面向大數據的挖掘比面向數據庫和數據倉庫的數據挖掘要復雜,因為大數據往往是無結構的,通常是用長的句子或短語來表達文檔類信息;有些則可能是半結構化的,當然也包括大量的異構信息、冗余信息等,對諸如廣告、導航條、動畫等無關信息的甄別與處理也都是需要考慮的問題。大數據挖掘也是一個交叉學科,它涉及信息檢索(信息檢索可以看成是大數據挖掘的初級階段)、人工智能、機器學習、概率論以及數據庫等。在大數據搜索和檢索中,常常需要對結果進行處理和內容挖掘。應用數據分析與挖掘方法,可以幫助人們從海量網絡信息中提取知識,為訪問者、站點經營者以及包括電子商務在內的基于因特網的商務活動提供決策支持。由于大數據的海量、冗余、異構等復雜特點,給傳統的數據挖掘技術提出了很多亟待解決的難題。
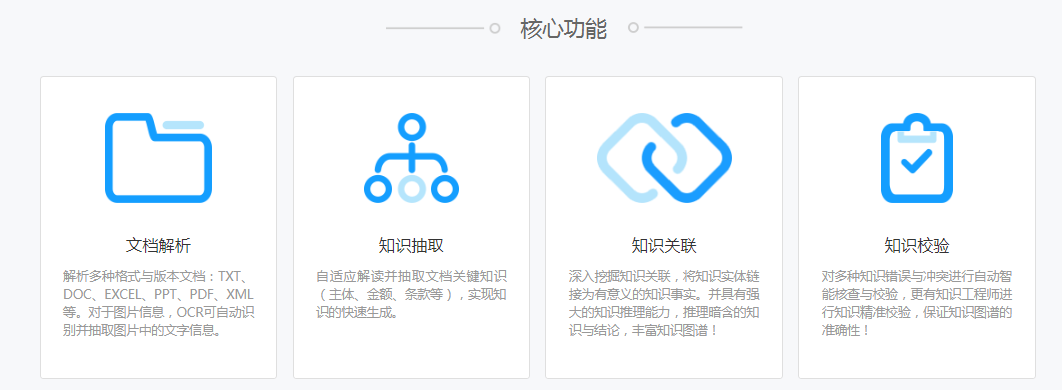
北京理工大學大數據搜索與挖掘實驗室張華平主任研發的NLPIR大數據語義智能分析技術是對語法、詞法和語義的綜合應用。NLPIR大數據語義智能分析平臺平臺是根據中文數據挖掘的綜合需求,融合了網絡采集、自然語言理解、文本挖掘和語義搜索的研究成果,并針對互聯網內容處理的全技術鏈條的共享開發平臺。
其中KGB(Knowledge Graph Builder)知識圖譜引擎是我們自主研發的知識圖譜構建與推理引擎,基于漢語詞法分析的基礎上,采用KGB語法實現了實時 的知識生成,可以從非結構化文本中抽取各類知識,并實現了從表格中抽取指定的內容等。KGB同時可以定義不同的動作,如抽取動作,并能自定義各類后處理程序。利用KGB知識圖譜引擎可以抽取到產品的詳細報價信息,方便進行下一步的數據挖掘與圖譜構建。