產品介紹
近年來�����,隨著云計算和物聯網概念的提出�,信息技術得到了快速的發展��,而大數據則是在此基礎上對現代信息技術革命的又一次顛覆�,所以大數據技術主要是從多種巨量的數據中快速的挖掘和獲取有價值的信息技術,因而在云時代的今天��,大數據技術已經被我們所關注�,所以數據挖掘技術成為最為關鍵的技術。尤其是在當前在日常信息關聯和處理中越來越離不開數據挖掘技術和信息技術的支持���。大數據�,而主要是對 的數據量較大的一個概括��,且每年的數據增長速度較快���。而數據挖掘����,主要是從多種模糊而又隨機、大量而又復雜且不規則的數據中����,獲得有用的信息知識,從數據庫中抽絲剝繭���、轉換分析�����,從而掌握其潛在價值與規律 ���。
在數據挖掘過程中,其技術流程主要是以下幾點:
首先做好數據準備工作�,主要是在挖掘數據之前,就需要對目標數據進行準確的定位���,在尋找和挖掘數據之前��,必須知道自身所需的數據類型�,才能避免數據挖掘的盲目性�����,在數據準備時,應根據系統的提示進行操作��,在數據庫中輸入檢索條件和目標����,對數據信息資源進行分類和清理���,以及編輯和預處理����。
其次是在數據挖掘過程中��,由于目標數據信息已經被預處理�����,所以就需要在挖掘處理過程中將其 正確的應用到管理機制之中���,因而數據挖掘的過程十分重要�����,所以必須加強對其的處理�����。
最后是切實加強管理和計算等專業知識的應用��,將數據挖掘技術實施中進行的總結和提取所獲得的數據信息與評估結果在現實之中應用����,從而對某個思想、決策是否正確和科學進行判斷�����,最終體現出數據挖掘及時的應用價值���。
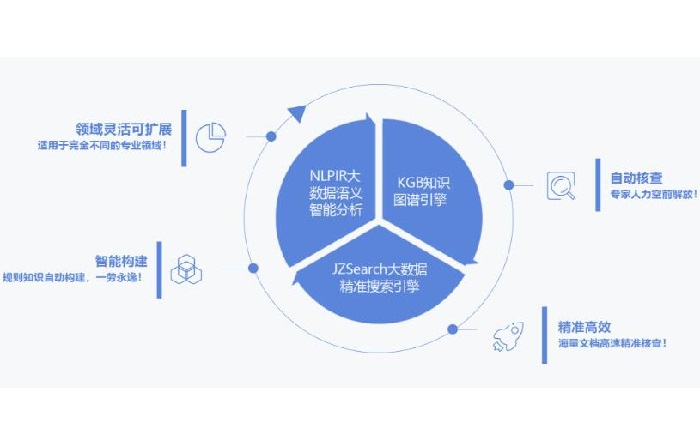
北京理工大學大數據搜索與挖掘實驗室張華平主任研發的NLPIR大數據語義智能分析技術是對語法�����、詞法和語義的綜合應用��。NLPIR大數據語義智能分析平臺平臺是根據中文數據挖掘的綜合需求,融合了網絡采集���、自然語言理解、文本挖掘和語義搜索的研究成果,并針對互聯網內容處理的全技術鏈條的共享開發平臺���。
其中KGB(Knowledge Graph Builder)知識圖譜引擎是我們自主研發的知識圖譜構建與推理引擎�,基于漢語詞法分析的基礎上,采用KGB語法實現了實時 的知識生成���,可以從非結構化文本中抽取各類知識,并實現了從表格中抽取指定的內容等�。KGB同時可以定義不同的動作,如抽取動作���,并能自定義各類后處理程序�。利用KGB知識圖譜引擎可以抽取到產品的詳細報價信息����,方便進行下一步的數據挖掘與圖譜構建。